中国组织工程研究 ›› 2024, Vol. 28 ›› Issue (17): 2766-2773.doi: 10.12307/2024.406
• 生物材料综述 biomaterial review • 上一篇 下一篇
机器学习在医用金属材料特性研究中的应用
史 榴1,梁鹏晨1,常 庆2,宋二红3
- 1上海大学微电子学院,上海市 201800;2上海交通大学医学院附属瑞金医院消化外科研究所,上海市胃肿瘤重点实验室,上海市 200020;3中国科学院上海硅酸盐研究所高性能陶瓷和超微结构国家重点实验室,上海市 200050
-
收稿日期:2023-07-14接受日期:2023-07-29出版日期:2024-06-18发布日期:2023-12-16 -
通讯作者:常庆,博士,研究员,上海交通大学医学院附属瑞金医院消化外科研究所,上海市胃肿瘤重点实验室,上海市 200020 宋二红,博士,副研究员,中国科学院上海硅酸盐研究所高性能陶瓷和超微结构国家重点实验室,上海市 200050 -
作者简介:史榴,女,1999年生,陕西省西安市人,汉族,上海大学在读硕士,主要从事深度学习算法在医用材料研发中的应用研究。 -
基金资助:国家自然科学基金资助项目(81670968),项目负责人:常庆
Application of machine learning in key properties of medical metal materials
Shi Liu1, Liang Pengchen1, Chang Qing2, Song Erhong3
- 1College of Microelectronics, Shanghai University, Shanghai 201800, China; 2Shanghai Key Laboratory of Gastric Neoplasms, Shanghai Institute of Digestive Surgery, Ruijin Hospital, Shanghai Jiao Tong University School of Medicine, Shanghai 200020, China; 3State Key Laboratory of High-Performance Ceramics and Ultrastructure, Shanghai Institute of Ceramics, Chinese Academy of Sciences, Shanghai 200050, China
-
Received:2023-07-14Accepted:2023-07-29Online:2024-06-18Published:2023-12-16 -
Contact:Chang Qing, PhD, Researcher, Shanghai Key Laboratory of Gastric Neoplasms, Shanghai Institute of Digestive Surgery, Ruijin Hospital, Shanghai Jiao Tong University School of Medicine, Shanghai 200020, China Song Erhong, PhD, Associate researcher, State Key Laboratory of High-Performance Ceramics and Ultrastructure, Shanghai Institute of Ceramics, Chinese Academy of Sciences, Shanghai 200050, China -
About author:Shi Liu, Master candidate, College of Microelectronics, Shanghai University, Shanghai 201800, China -
Supported by:National Natural Science Foundation of China, No. 81670968 (to CQ)
摘要:
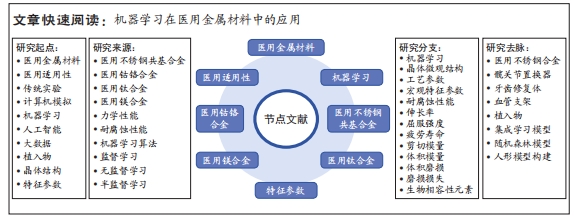
文题释义:
医用金属材料:是在医学领域中广泛应用的特殊金属材料。这些金属材料通常具有优异的生物相容性、耐腐蚀性和力学性能。常见的医用金属包括不锈钢、钛合金和钴铬合金等,由于其良好的特性,医用金属材料在植入物制造、手术器械、牙科修复和骨科手术等领域得到广泛应用。机器学习:是人工智能领域的一个分支,它是通过构建和训练算法来使计算机系统从数据中学习,并根据学习的知识做出决策或预测。机器学习的核心思想是通过分析大量数据,找出其中的模式和规律,并用这些规律来做出预测或分类。
背景:机器学习与医用金属材料的结合,弥补传统实验和计算模拟的低效性和高成本的不足,通过分析大量数据快速准确地预测金属材料特性,优化材料设计和性能,提高医学应用的安全性和效率。
目的:总结并归纳机器学习在医用材料特性中的研究进展及不足。方法:由第一作者通过计算机检索中国知网、PubMed、X-MOL和Web of Science数据库2013年1月至2023年4月的相关文章。中文检索词为“医用金属材料机器学习,医用钛合金,医用镁合金,医用金属材料性能”,英文检索词为“machine learning medical metal materials,medical stainless steel alloy,medical cobalt-chromium alloy,medical titanium alloy,medical magnesium alloy”,最终纳入70篇相关文献进行归纳总结。
结果与结论:①随着传统实验和计算模拟方法所产生的大量数据的可获取性提高,机器学习作为材料设计方法的引入为材料科学研究开辟了新的范式。②机器学习工作流主要分为4个部分:数据收集及预处理、特征工程、模型选择及训练和模型评估,每个环节不可缺少。③医用金属材料分为:不锈钢共基合金、钴铬合金、钛合金和镁合金。针对不锈钢共基合金,机器学习预测其力学性能,要提高机器学习的泛化能力;针对钴铬合金,机器学习预测其力学性能,可得出钴铬合金为髋关节植入物的最佳材料;针对钛合金,机器学习预测其力学性能,可选择出力学性能最优异的植入物;针对镁合金,机器学习预测其耐腐蚀性和力学性能,集成模型可准确预测镁合金的力学性能,随机森林模型可预测镁合金作为血管支架时的最优元素含量。④机器学习在医用材料领域存在一定局限性,如模型相对滞后、数据未能标准化及泛化性较低;未来研究解决此类问题应充分利用深度学习和分割算法技术,使用统一标准数据,改善模型提高泛化能力。
https://orcid.org/0009-0006-7587-9541(史榴);https://orcid.org/0000-0001-7568-4070(常庆)
中国组织工程研究杂志出版内容重点:生物材料;骨生物材料;口腔生物材料;纳米材料;缓释材料;材料相容性;组织工程
中图分类号:
引用本文
史 榴, 梁鹏晨, 常 庆, 宋二红. 机器学习在医用金属材料特性研究中的应用[J]. 中国组织工程研究, 2024, 28(17): 2766-2773.
Shi Liu, Liang Pengchen, Chang Qing, Song Erhong. Application of machine learning in key properties of medical metal materials[J]. Chinese Journal of Tissue Engineering Research, 2024, 28(17): 2766-2773.
2.1.1 数据收集及预处理 在机器学习工作流程中,数据收集和预处理是构建精确预测模型的关键步骤。训练数据集的大小和质量对于模型性能起着决定性作用[12]。研究人员通常致力于选择具有显著代表性的数据,这种选择过程不仅确保了数据的质量和可靠性,还为问题的有效解决提供了基础。当前,在材料领域大数据启发下,已经建立了多个与材料相关的开发数据库,为机器学习研究提供了丰富的数据资源。例如,晶体学开放数据库(http://www.crystallography.net/cod/),该数据库由剑桥大学开发,包含有机、无机、金属有机化合物和矿物晶体结构等数据[13];
AFLOW材料数据库(http://aflowlib.org/),该数据库由杜克大学开发,包含 3 528 653种材料化合物,具有超过733 959 824种计算属性[14];开放量子材料数据库(https://www.oqmd.org/),由美国西北大学开发,包含1 022 603种材料的DFT计算热力学和结构特性[15];计算二维材料数据库(https://cmr.fysik.dtu.dk/c2db/c2db.html),该数据库包含大约
4 000种二维(2D)材料的结构、热力学、弹性、电子、磁性和光学特性[16];材料云数据库(https://www.materialscloud.org/discover/menu),该数据库包含三维晶体、二维晶体、金属有机框架等多个子数据库,可用于碳捕获和甲烷储存等应用[17];JARVIS-DFT 数据库(https://www.nist.gov/programs-projects/jarvis-dft),专注于基于密度泛函理论(DFT)的材料性能预测,保存了大约40 000种块状材料和大约1 000种低维晶体材料的多种性能数据,如形成能、带隙、介电常数、磁矩、红外强度和电场梯度等[18];有机材料数据库(https://omdb.mathub.io/),是一个开放访问的三维有机晶体电子结构数据库,提供了基于数据挖掘和机器学习技术的搜索查询工具[19]。
数据预处理在机器学习中是一个至关重要的步骤,它包括数据采样、异常值处理、数据离散化和数据标准化4个主要步骤。数据采样旨在使用更少的数据构建高性能的预测模型,同时确保预测准确性不受影响[20-21]。异常值处理涉及检测并处理偏离数据正常范围的值,常用的方法包括基于正态分布和基于监督学习的异常值检测[22]。对于包含数值属性的数据,需要将所有数值转换为离散值,以满足许多机器学习模型的要求,这一过程称为离散化[23]。数据标准化是通过缩放数值将其转化到指定的范围,是涉及距离计算或神经网络分类框架的重要步骤[24]。常用的数据标准化技术包括十进制缩放、Z-score标准化和min-max标准化等[25]。数据标准化有助于提高神经网络的收敛速度,并显著提升基于距离计算算法的准确性。
数据收集和预处理在机器学习领域占用较多时间,对于一个研究课题,前提是需要收集足够数量和质量的数据,并对数据进行正确的预处理。
2.1.2 特征工程 是机器学习中数据准备的核心任务之一,它涉及从原始数据中提取特征以构建适合建模的特征集合,以提高模型的预测性
能[26]。特征工程包括应用变换函数,如算术和聚合运算符,在给定特征上生成新特征[27]。在深度学习领域,由于深度神经网络具备自动提取特征的能力,特征工程通常不需要手动构建,但这也导致模型可解释性降低[28]。然而,在大多数机器学习算法中,特征工程对于模型的性能至关重要,因此在实际应用中,特征工程的设计是耗时的关键步骤[29]。
特征工程常用的方法包括独立成分分析、类别编码器、聚类和主成分分析等[30]。独立成分分析用于将多个观测信号分解为独立的非高斯分布成分,以提取潜在的重要信息,改善模型性能。类别编码器用于处理分类变量,并将其转换为机器学习模型可以处理的数值形式。聚类方法有助于发现数据中的潜在模式和结构,为特征工程提供数据集信息。主成分分析用于降低数值型数据的维度,通过线性变换将原始数据投影到一组新的维度上,以保留尽可能多的信息并减少特征数量[31]。这些方法在特征工程中发挥着重要的作用,能够提取有用的特征,降低数据的维度,并帮助构建更优的机器学习模型。
2.1.3 模型选择及训练 在具备合适格式的充足数据之后,即可建立用于材料分析的模型。建模过程包括选择适当的算法、利用训练数据进行训练,最后进行预测。如图3所示,机器学习按数据类型可分为监督学习、无监督学习和半监督学习。
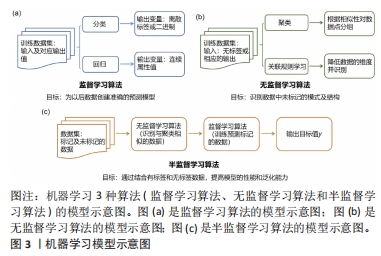
监督学习:在监督学习中,如图3(a)所示。数据集被视为一个训练集,包含输入变量及其相应的输出变量。监督学习算法的目标是从训练数据中学习输入(结构)和输出(属性)之间的映射函数。主要目标是在训练后构建一个能够对新数据进行可接受水平预测的模型。监督学习可以分为回归和分类两种主要类型,它们的目标都是建立能够从已知输入变量预测输出值的模型,不同之处在于输出变量的类型。在回归问题中,要预测的变量是连续且多样化的,例如熔点、带隙和弹性模量等。回归算法包括线性回归、高斯过程回归以及决策树回归等方法。
另一方面,在分类问题中,算法的目标是对输入数据进行标签预测,即对输入数据赋予特定的分类标签。这些标签是离散且单一的,用于表示不同类别,例如材料是否导电、是否多孔等。常见的分类算法包括线性判别分析、k最近邻、朴素贝叶斯、支持向量机和核岭分类等。例如,GHIRINGHELLI等[32]使用核岭分类算法以及从价轨道的能级和半径得出的描述符来预测闪锌矿和纤锌矿型晶体结构之间的晶体排列。在模型选择和训练过程中,理解监督学习中的这些基本概念和方法,并根据具体问题和数据特点选择合适的算法,对于建立高性能的预测模型至关重要。
无监督学习:该算法如图3(b)所示,其目标是在没有预先标记的数据上发现数据的内在模式和结构。与监督学习不同,无监督学习不依赖于对应输出变量的信息,而是通过对输入数据进行推断和聚类,从中发现数据的隐藏特征和关系。无监督学习在没有人工监督或指导的情况下,探索数据的潜在结构和规律,提供了对数据的深入理解和分析的有价值工具。
无监督学习算法可大致分为两种类型:聚类和降维。在聚类算法中,机器学习流程将数据划分为几个具有相似特征的记录组,而不预设这些组的性质(与监督学习分类任务不同)。降维算法可以辅助发现数据中隐藏模式和群组结构,为数据提供洞察信息。降维算法用于减少数据的维度,使其更易于可视化和处理,保留数据的关键特征,降低数据的复杂性。在处理高维数据集,特别是在图像处理任务中,降维算法具有重要作用[33]。
半监督学习:是一种介于监督学习和无监督学习之间的学习方法。如图3(c)所示工作流程,在半监督学习中,虽拥有大量的输入数据,但只有有限数量的相应输出数据。半监督学习旨在从数据集的标记部分学习,训练准确的模型。首先,利用无监督学习算法对数据进行聚类或相似性分析,将相似的数据点分组;然后,利用监督学习技术对这些已标记的数据进行训练和预测。目前,半监督算法广泛应用于文本和语音分析、互联网内容分类以及蛋白质序列分类应用等领域。例如,COURT等[34]
使用半监督学习方法创建了一个包含39 822个居里和内尔温度材料数据库,该数据库通过对68 078篇化学和物理文章的文本挖掘,应用自然语言处理和半监督关系提取算法从文本中获取材料属性值。
半监督学习的发展为利用大量未标记数据进行模型训练提供了有效的方法,对于数据集有限或成本较高的情况下仍能取得良好的预测效果,在实际应用中依旧具有重要意义和潜力。
2.1.4 模型评估 正如上文所述,机器学习的主要目标是训练和生成一个有效的计算模型,能够准确预测结果。为了确定模型的准确性,不能仅仅依靠对训练数据集的验证结果。最佳方法是评估经过训练的机器学习模型在未包含在训练集中的数据上的性能。从给定规格的数据集开始,采用交叉验证技术比简单地将数据分为训练集和验证集更加有效,其中最常用的交叉验证方法之一是 k 折叠交叉验证。在此方法中,数据集被分为多个子集,在机器学习训练过程中,使用所有子集作为训练集来训练模型,并将一个子集保留作为测试集。训练和评估过程会重复多次,每次使用不同的数据子集进行验证。
在评估机器学习模型时,其中一个要考虑的问题是模型的复杂度是否与数据的复杂度相匹配。如果数据不够详细或模型过于简单,生成的模型可能会出现偏差,这种称为欠拟合。相反,如果模型过于复杂,参数过多,就可能出现过度拟合。为了生成最佳模型,平衡欠拟合和过度拟合,通过调整超参数是非常重要的。
为了评估机器学习超参数优化的结果是否提高了算法的准确性,需要根据问题的类型选择合适的评估指标。对于回归问题,常用的评估指标包括相关系数(R-squared,R2)、平均绝对误差(mean absolute error,MAE)、平均绝对百分比误差(mean absolute percentage error,MAPE)和均方根误差(root mean square error,RMSE)[35]。分类模型准确性的评估指标包括分类准确率、召回率、准确率、受试者工作特征曲线、铰链损失、逻辑回归损失、混淆矩阵、覆盖误差、汉明距离、标签排名平均准确率和排名损失[36]。常用的聚类问题的模型评估指标包括兰德指数、等高线系数和互信息[37]。
2.2 机器学习研究医用金属材料 由于传统实验以及计算模拟方法对医用金属材料的研究中存在一定的局限性,诸如材料跨尺度设计、本征性能与工艺设计关联以及研究效率低和成本昂贵等。随着大数据的发展完善,机器学习作为第四研究范式,在医用金属材料取得显著的发展。
根据输入特征参数的类型,机器学习在医用金属材料性能预测中可以分为两大类:宏观特征参数和微观特征参数。宏观特征参数主要涉及材料制造过程中的工艺参数、扫描速度、老化参数及制品的厚度等。微观特征参数则是包括晶格常数、晶粒存能密度和晶体微观结构的变化以及晶体元素组成等结构内部属性。在医学材料领域,评估材料是否适用于医学领域的关键因素是其材料的关键特性能否达到人体骨骼及组织承受范围。因此,根据文献报道,对于医用金属材料特性研究,最广泛的是对材料成分、结构或工艺与特性之间关系的建模和预测。
在这篇综述文章中,如表1所示,将医用金属材料分成了:不锈钢共基合金、钴铬合金、钛合金及镁合金共4类,由于各个金属材料都存在特性上的弊端,因此将分别展示机器学习在这些金属材料中采用宏观特征参数和微观特征参数对金属材料特性改善以及性能预测的应用[38-43]。

2.2.1 不锈钢共基合金 此合金是外科领域中首个成功应用的金属植入材料。由于材料易于制造,并且可以通过常规灭菌程序进行灭菌,因此广泛应用于骨科和植入设备,具有优异的耐腐蚀性[38-39]。机器学习在不锈钢合金特性预测领域的应用主要集中在力学性能方面,特征参数主要包括以下2个方面:①晶粒存能密度等晶体微观结构;②激光功率、马氏体基体、老化时间及老化温度等工艺参数。
针对微观特征参数的研究,WENYE等[44]从晶体微观结构角度出发,以等轴晶粒和柱状晶粒的晶粒存能密度和峰值应力作为特征输入,通过回归神经网络机器学习模型预测不锈钢的疲劳寿命。实验结果显示两种微观结构预测值与计算值之间具有良好的一致性。然而,在中低至中高周期疲劳过程中,随着数据量的增加,测试误差也相应增大,这是因为金属在中低至中高周期疲劳过程中的微观变形使得内部结构变得比较复杂,涉及多种力学和物理现象。文章使用的机器学习模型不能很好地捕捉这些复杂性,导致误差增大。由此看来,回归神经网络模型可准确预测晶体在低至中周期疲劳寿命。
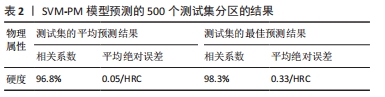
针对宏观特征参数的研究,DUAN等[45]选取了先前实验中的139个L-PBF不锈钢316 L样品数据,以激光功率P、扫描速度v和材料层厚t为特征参数,利用自适应神经模糊推理系统(ANFIS)预测断裂机制和疲劳寿命。结果表明真实值与预测值具有较高一致性。然而,该模型的适用性仅限于训练实验范围。因此,选择具有代表性的输入变量并建立大型数据库进行训练对提高模型泛化能力至关重要。为此,SHEN等[46]开发了一种结合支持向量机和物理冶金原理指导的新型机器学习算法模型。通过仅使用102个UHS不锈钢样本,以马氏体基体、残余奥氏体及沉淀物的含量和形态、老化温度和老化时间作为特征参数,成功预测了不锈钢的硬度。如表2所示,测试集的平均预测结果与最佳预测结果基本一致,表明该模型具有优异的泛化能力和高预测精度,在小数据集上表现尤为突出。
因此,虽然各种机器学习模型在不锈钢力学性能研究中取得了一定的成果。然而,仍需关注提高模型泛化能力、扩大训练数据集以及选择更具代表性的输入变量等问题。此外,实际应用中,可以尝试结合多种模型以获得更精确的预测。
2.2.2 钴铬合金 相较于其他金属生物材料,钴铬基合金因其卓越的耐磨性而在人工膝关节、髋关节、骨科植入物和牙科修复体等应用领域中得到广泛使用[40-41]。然而,其较高的模量可引起股骨头与植入物之间的应力屏蔽,并且股骨头与植入物的直接接触可能会随时间推移导致磨损。因此,研究人员对钴铬合金的附加合金元素进行了研究,以改善力学性能来提高其力学性能,由于钴铬合金的力学性能的主要影响因素是合金的晶体结构,所以对于钴铬合金的研究,机器学习主要从微观特征参数入手,通过准确预测钴铬合金的力学性能,从而有效应对合金成分设计的挑战。
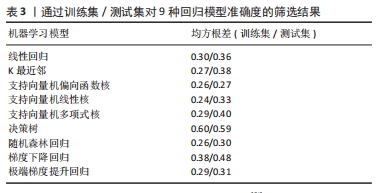
针对多组分钴铬合金,ZHAO等[47]使用人工神经网络模型将元素特征与长期排序相结合,以观察不同状态下微观结构中有序程度和方式的变化。通过选取价电子浓度、原子尺寸失配、配置熵、电负性差和混合熔点作为输入特征来预测晶格畸变和电负性,准确率达到了82%,有效捕获合金微观结构的变化。CHANG等[48]使用人工神经网络的方法预测Al-Co-Cr-Fe-Mn-Ni合金的硬度,并探究材料成分和性能之间的联系。通过将硬度、固体密度和原子质量作为特征输入,通过与实验硬度进行比较,显示出良好的一致性(R2=0.94;MAE=36 HV)。WEN等[49]将机器学习与传统实验相结合,探究Al-Co-Cr-Cu-Fe-Ni合金的硬度,将各个元素的原子占比范围内组成的合金对应的硬度作为数据集,将高熵合金的设计作为一个迭代循环,结合了机器学习建模、实验设计算法和实验反馈,实现了高熵合金的设计。研究发现,合金成分逐渐稳定,并且有35种合金的硬度值高于训练数据集中的最佳值。CHEN等[50]采用9种机器学习回归模型和分子动力学模拟,回归模型筛选结果如表3所示,支持向量机偏向函数核的均方根差最小,其预测结果最好。其次将价电子浓度VEC,空位形成能量Ev和内聚能的不匹配DEC作为输入特征,通过支持向量机偏向函数核预测高熵合金的屈服强度,准确率达到97%。结果发现,V5Cr16Fe9Co35Ni35 具有最高的屈服强度,并且随着迭代次数的增加,机器学习模型的鲁棒性得到了提高。
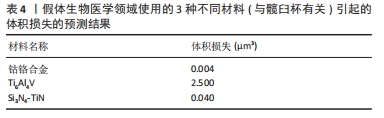
最后,针对非多组分钴铬合金,MILONE等[51]利用机器学习算法和有限元分析对植入体进行建模,并根据材料的磨损体积损失评估髋关节植入物假体手术的最佳材料。研究人员对人形模型进行建模,并对人体的坐、站、走进行动作捕捉,观察髋关节和脊柱以及膝盖和臀部的角度形态变化,同时选取了摩擦系数、磨损系数、压力指数和滑动速度指数作为线性回归模型的特征参数,预测钴铬合金、Ti6Al4V以及Si3N4-TiN的体积损失。结果如表4所示,钴铬合金对在磨损(与股骨头相关)引起的体积损失方面表现更好,并将所得结果与文献研究进行了比较,显示出良好的一致性。同时,该结果表明,相对于传统条件,例如髋关节模拟器,开发的人形模型并对其进行动作捕捉是一种有效的替代方案,用于估计作用在髋关节植入物上的负载和旋转条件,并取得了优异的结果。
综上所述,研究人员使用人工神经网络和支持向量机等机器学习算法来预测合金的性能和微观结构,通过将元素特征和其他属性作为输入特征,成功地实现了对合金硬度、屈服强度等性能的准确预测。此外,针对非多组分钴铬合金的研究,使用机器学习算法对植入体进行建模,评估髋关节植入物的最佳材料,并通过动作捕捉对人体模型进行了实验验证。由此可以看出,机器学习可以加速材料性能预测和合金设计过程,同时机器学习模型的高准确率和鲁棒性使其成为研究人员有效探索新材料和优化合金性能的有力工具。此外,结合机器学习和实验验证的方法,可以更好地理解材料的行为和性能,为医用金属材料的发展和应用提供有价值的信息。
2.2.3 钛合金 钛及其合金是应用最广泛的金属植入物材料,因为与其他金属材料相比,钛及其合金具有优异的生物相容性、低密度、高强度。对于钛合金而言,关键特性在于选择具有类似于人骨的低模量,以避免刚度不匹配和应力遮挡问题[42]。因此,对于钛合金的特性研究,机器学习主要从其模量入手,加速开发新型优异钛合金。
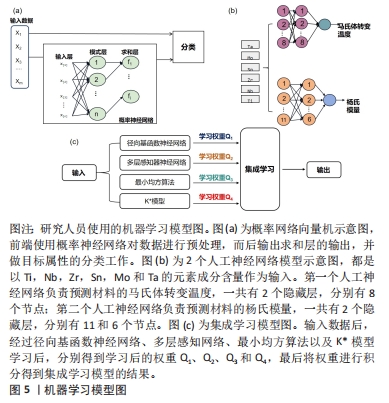
针对输入钛合金微观特征参数研究中,ZOU等[52]使用基于门捷列夫周期表形式的高通量计算生成的数据,包括电子功函数、费米能、成键电荷密度和晶格畸变能。然后采用基于径向基核函数的支持向量机算法,发现预测的含β单相的Ti-7443合金与F2066合金相比,具有48 GPa的低杨氏模量、良好的屈服强度和低Mo含量的伸长率,并且可以从高通量计算的电子特性中揭示Ti-7443合金力学性能优异的原因,因此,该方法提供了对组成-结构-属性关系的有效见解,而且还可以以更有效的方式设计高强度延展性钛合金。IZONIN等[53]使用了一种混合机器学习算法(概率神经网络支持向量机)对医学植入物钛基粉末(Ti-6Al-4V和Ti-Al-V-Zr)进行性能评估。
如图5(a)所示,即为概率神经网络向量机,是将概率神经网络用作预处理数据的工具,输出为概率神经网络的求和层的输出,以便支持向量机分类器进一步使用其工作结果。研究人员将颗粒表面生长物的含量,粉末颗粒的直径范围和粉末颗粒的形式作为特征输入,预测医学植入物钛合金粉末混合物的高质量或低质量性能的分类任务。结果表明,概率神经网络支持向量机的预测召回率在91%,可有效地分辨合金粉末的高低质量,用于解决钛粉合金烧结前通过增材技术估算钛粉合金的微观组织缺陷和性能问题。使用该模型将显著减少制造生物医学植入物的材料、时间和人力资源。WU等[54]使用人工神经网络发现了具有低模量的新型β钛合金。
如图5(b)所示,研究人员使用2个人工神经网络模型分别预测钛合金的马氏体转变温度和杨氏模量,2个人工神经网络输入的数据都为Ti,Nb,Zr,Sn,Mo和Ta的元素成分含量。预测结果发现,杨氏模量的预测RMSE为12.7 GPa,马氏体转变温度的预测RMSE为33.4 K,结果较好,并发现了一种类骨模量的合金:Ti-12Nb-12Zr-12Sn,该合金模量小于50 GPa,并且根据研究人员对合金成本的调查,发现该合金的成本最低,因此,该算法模型可以快速、低成本地找到低模量钛合金,展示了机器学习方法在加速钛合金空间探索方面的前景。RAJ等[55]运用多元线性回归分析、人工神经网络和模糊推理系统3种机器学习算法,以合金元素成分为特征输入,预测不同元素成分下的钛合金的弹性模量。研究发现,Al,Zr,Fe,Sn和Cr等合金元素在降低弹性模量方面起着最重要的作用,而对钛合金的强度没有太大影响。同时LIU等[56]也是将合金成分作为数据集特征输入,利用梯度增强决策树分类模型预测微观结构,利用随机森林回归模型预测杨氏模量,预测结果与实验一致,并成功研制出具有单β相组织和杨氏模量69.91 GPa的Ti-13Nb-12Ta-10Zr-4Sn
合金。
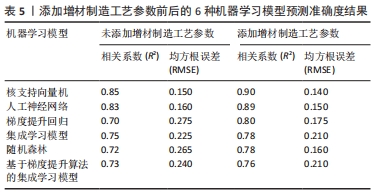
针对输入钛合金宏观特征参数研究中,ZHENG等[57]提出了一种将径向基函数神经网络、多层感知网络、最小均方算法以及K*模型集成的模型,如图5(c)所示。以牙齿修复体钛合金在人工唾液中的咬合力,滑动频率和周期作为特征输入,预测修复体的磨损损失。结果表明,集成学习模型的误差在3%-4%之间,在预测牙齿修复材料磨损损失方面具有良好的稳定性和高精度。当钛合金中含有多种元素且分布均匀时,就形成了一种被称为高熵合金的新材料。高熵合金能够将多个优异的特性结合起来,因此成为了近年来钛合金研究的热点。BHANDARI等[58]通过随机森林回归模型对MoNbTaTiW和HfMoNbTaTiZr高熵钛合金的硬度进行预测,硬度通过屈服强度的大小来表示,以体积模量、熔化温度为重要特征,预测结果为随机森林模型的准确率达到了95%。然而,该模型针对其他合金的预测时精度较低,缺乏泛化能力。为了提高模型的泛化能力,SUN等[59]将相图计算与极限梯度提升模型相结合,以Ta含量、熔点和混合熵为特征参数输入预测高熵合金的硬度,预测结果为准确率达到97.8%,并设计出具有理想硬度的Ti-Zr-Nb-Ta难熔高熵合金,最后用实验验证发现设计的高熵合金与实验结果高达98%的相关性,表明该方法显著提高了模型的泛化能力,能够以较高的准确度识别原始输入数据集之外的有用高熵合金。Zhou等[60]采用6种机器学习模型,根据增材制造工艺参数来预测高熵合金硬度,并通过增材制造实验制备4种高熵合金验证预测结果。结果如表5所示,纳入增材制造工艺参数作为特征参数后,各模型预测精度均有不同程度提升,表明将增材制造工艺参数融入机器学习模型能够有效提高高熵合金硬度的预测精度。
综上可见,在医用材料研究中,机器学习方法为钛合金等材料的性能预测和设计提供了新的途径。研究人员利用机器学习算法,如支持向量机、概率神经网络和人工神经网络等,结合特征参数的输入,成功预测了钛合金的硬度、弹性模量和疲劳损失等关键性能指标。这些预测结果在实验验证中表现出较好的稳定性和高精度,使得机器学习方法成为医用材料研究中的有效工具,加快筛选具备医用适用性的植入物。同时机器学习在高熵合金等新材料研究中的应用,为探索新型合金材料提供了前所未有的机会。研究人员结合机器学习模型和相图计算等方法,成功识别出高熵合金中有用的组分,取得了优异的预测结果。这种机器学习方法不仅提高了高熵合金的预测精度,而且显著降低了研发新材料的时间和成本,为医用材料的开发提供了新的思路。最后,研究人员通过结合实验验证和理论模拟将机器学习与传统方法相结合,有望更好地解决医用材料的复杂问题,推动医用材料领域的发展和应用。总体而言,机器学习在医用材料研究中展现出巨大的潜力,为未来医疗器械和植入物的开发提供了有力支持。
2.2.4 镁合金 作为一种新型医用材料,镁合金具有出色生物可降解性。当镁合金作为植入材料进入人体组织后,可以随着人体代谢逐渐降解,无需进行二次取出,并且没有毒性。然而,镁合金的低耐蚀性和力学性能在一定程度上限制了其在医疗领域的应用[43]。为了克服这些局限性,研究人员利用机器学习技术来优化镁合金性能,从而提升其在医疗领域的应用潜力。
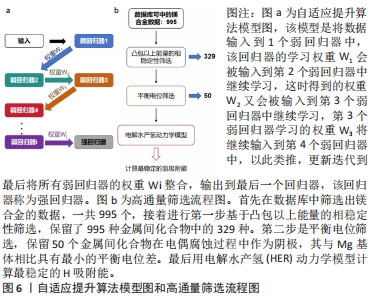
针对输入镁合金微观特征参数研究中,JAAFREH等[61]从AFLOW数据库[62]中筛选出3 591种镁合金金属间化合物,选取了晶体的带隙、形成能量、稳定性及其松弛晶体参数等271个特征来预测化合物的剪切模量和体积模量,并采用自适应提升算法模型,也是一种集成算法模型,如图6a所示,该模型是将每个弱回归器进行学习迭代生成强回归器,从而预测材料的特性。预测结果表明,体积模量和剪切模量的平均误差分别为4.92%和16.9%,相关系数R2得分分别为0.94和0.92并通过该模型筛选出来的MgB13和MgPd2具有优异的剪切模量和体积模量,最后用第一性原理计算两种化合物的电荷密度分布和电子定位函数解释了两种化合物优异性的原因,从而得到验证。这一研究表明,该模型可用于加速晶体材料中剪切模量和体积模量的计算,并且结合第一性原理计算电荷密度分布和电子定位函数的分析还为确定镁基合金的性能-结构关系提供了一个额外的工具。WANG等[63]使用高通量筛选来抑制电偶腐蚀,图6b为高通量筛选流程图,通过筛选获得二元镁金属间化合物,该化合物对镁合金的电偶腐蚀具有较小的热力学驱动力和低氢吸附能,结果发现Y3Mg,Y2Mg和 La5Mg可抑制镁合金的电偶腐蚀。最后研究人员选取功函数和加权第一电离能为特征,用K近邻算法模型预测合金的腐蚀电位,结果发现大多数Mg-RE二元金属间化合物与Mg基体具有接近的平衡电位,并与DFT验证一致。机器学习模型可加速高通量筛选的过程,高通量与机器学习的结合不仅预测了一些有前途的二元Mg金属间化合物,可以阻碍电偶腐蚀,而且还为耐腐蚀金属合金设计提供了一种高通量筛选策略,这可能对未来的实验具有指导意义。
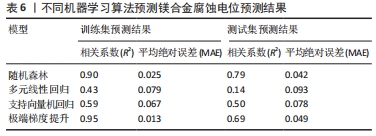
腹主动脉瘤是导致死亡的最普遍和最危险的疾病之一。最近,血管内动脉瘤修复优于开放主动脉手术,因为它是一种安全可靠的技术,将支架移植系统放置在主动脉瘤内,它旨在设计一种具有生物友好合金元素的Mg可生物降解合金,该合金可增强合金的耐腐蚀性和机械性能,设计用于腹主动脉瘤修复的支架。因此,SUH等[64]和LU等[65]都使用随机森林模型预测了镁合金的力学性能和腐蚀性能。两者使用的数据均包括元素和力学参数,不同之处在于JSUH等[64]利用随机森林将锌确定为极限抗压强度和体外腐蚀速率的关键决定因素,并提出了0.5%≤Zn质量分数≤1.5%,0.6%≤Mn质量分数≤1.2%,0.0≤Sr质量分数≤0.6%和0.0≤Ca质量分数≤0.15%最佳含量,通过该含量生成的镁合金的极限抗压强度为244-305 MPa,体外腐蚀速率为0.31-0.83 mm/年,可有效植入到血管中,并为承重镁植入物提供了最优元素含量,促进镁合金植入体的开发。而LU等[65]比较了4种机器学习算法:随机森林、多元线性回归、支持向量机回归和极端梯度提升预测镁合金的腐蚀电位如表6所示,结果表明随机森林算法提供了比其他3种机器学习算法最准确的预测,此外,研究人员利用随机森林模型发现Mg-Al合金比纯Mg合金具有更高的腐蚀电位,并使用了特征创建(将化学成分特征转换为原子和物理特性),因此输入特征不限于特定的化学成分,提高了机器学习模型的泛化性。由此可以看出,随机森林模型在预测镁合金性能呈现出优异的趋势,为承重镁植入物提供合金设计指导。
针对输入镁合金宏观特征参数研究中,Li等[66]采用自适应神经模糊推理系统和支持向量机预测镁合金植入物的屈服强度和极限抗拉强度,将严重塑性变形参数(包括金属成形过程的种类、通过次数和过程温度)作为特征输入,研究了严重塑性变形与镁植入物力学性能之间的关系。最后用基因表达编程和基因编程验证了机器学习的预测能力,预测结果表明模型的准确率均高于0.8。研究表明基于自适应神经模糊推理系统和支持向量机的模型在预测镁合金用于骨折固定和骨科植入物的力学行为方面具有较高的准确性。Mi等[67]使用粒子群优化算法优化人工神经网络模型预测镁合金的机械性能(屈服抗拉强度、极限抗拉强度和伸长率),并以合金成分、挤压工艺参数等11个参数作为特征输入。预测结果分别为R2:0.98、0.96和0.95,准确度较高。最后研究人员利用逆向设计模型反向搜索满足目标性能条件的成分和工艺参数的组合,该模型平均计算精度约为7%。经过筛选,设计了4种具有高性能和低成本属性的合金,并通过实际熔炼和挤压实验进行了验证,误差分别为7.8%、6.6%、8.6%和6.3%。结果表明,逆向设计模型可用于设计和开发更多新型高性能、多组分的镁合金,无需先验知识和深入研究机制。该模型的泛化能力较强,只需更改数据集即可用于其他类型的合金设计。XU等[68]基于人工神经网络和支持向量机算法,使用加工参数(均质温度和持续时间,轧制/挤出温度和速度,退火温度和持续时间)作为特征输入,包含112个数据的数据集构建了2个模型,2种模型在预测屈服强度、极限抗拉强度和拉伸伸长率方面都取得了良好的准确性。预测结果为人工神经网络和支持向量机模型的都取得了良好的准确性,并以此开发了一种新的挤压镁合金,并将该合金与预测值相比,准确度较高,说明该模型的泛化能力较强,加速镁合金力学性能的开发。Mi等[69]对90种机器学习模型进行了汇总比较,结果表明决策树和人工神经网络的准确率均在80%左右。此外,Mi等[69]还成功开发了4种新型Mg-Mn合金,具有超细晶粒和预期力学性能。LIU等[70]采用极限梯度提升模型,以老化参数为特征预测材料硬度,并成功合成了一种新型Mg-Al-Sn-Zn-Ca-Mn合金,该合金的维氏硬度值为110.5 Hv,超过了文献初始数据集中的最高值(102.5 Hv);最后探究该合金有超高硬度的原因,其原因是Mg17Al12和Mg2Sn老化过程中生成了沉淀物,提高该合金的硬度。该方法可有效生成超高硬度的镁合金,并加速高强度镁合金的开发。
综上所述,在镁合金微观特征参数研究方面,多个研究团队采用机器学习方法,如自适应提升算法、K近邻算法及随机森林等,结合大量特征参数来预测镁合金的性能,这些预测结果显示出较好的准确性和稳定性,为材料性能优化和设计提供了重要依据。其中,集成算法模型(如自适应提升算法)在预测镁合金的体积模量和剪切模量方面取得了较高的准确率。此外,机器学习方法结合第一性原理计算等分析手段,还为确定镁合金性能与结构关系提供了额外的工具。针对镁合金的强度以及腐蚀性能,研究人员使用多个机器学习模型进行对比,发现随机森林表现出较好的预测准确度,并利用该模型预测出镁合金最优元素含量比,该方法在设计用于腹主动脉瘤修复的支架时,提供了有益的元素含量指导,促进了镁合金植入体的开发。在宏观特征参数研究中,机器学习模型,如支持向量机、随机森林和人工神经网络等,用于预测镁合金的力学性能和腐蚀性能。这些模型在预测准确率方面表现出优异的趋势,并有助于加速镁合金材料的设计和优化。总体而言,机器学习在镁合金研究中的应用为材料性能预测、设计和优化提供了新的有效途径,有望推动镁合金材料的进一步发展和应用,尤其在医用植入物等领域具有重要的实际应用价值。

| [1] WALLEY KC, BAJRALIU M, GONZALEZ T, et al. The chronicle of a stainless steel orthopaedic implant. Orthop J Harv Med Sch. 2016;17:68-74. [2] LI H, WANG Z, ZOU N, et al. Deep-learning density functional theory Hamiltonian for efficient ab initio electronic-structure calculation. Nat Comput Sci. 2022;2(6):367-377. [3] XU H, STOLLER RE, BÉLAND LK, et al. Self-evolving atomistic kinetic Monte Carlo simulations of defects in materials. Comput Mater Sci. 2015;100:135-143. [4] LEI H, LI X, WANG J, et al. DFT and molecular dynamic simulation for the dielectric property analysis of polyimides. Chem Phys Lett. 2022;786:139131. [5] CHEN LQ, ZHAO Y. From classical thermodynamics to phase-field method. Prog Mater Sci. 2022;124:100868. [6] CHEN H, FAN D, HUANG J, et al. Finite element analysis model on ultrasonic phased array technique for material defect time of flight diffraction detection. Sci Adv Mater. 2020;12(5): 665-675. [7] ANKIT A, ALOK C. Perspective: materials informatics and big data: realization of the “fourth paradigm” of science in materials science. Apl Mater. 2016;4(5):053208. [8] BATRA R, SONG L, RAMPRASAD R. Emerging materials intelligence ecosystems propelled by machine learning. Nat Rev Mater. 2021;6(8):655-678. [9] JING W, XUAN C, XIANG YS, et al. Machine learning in materials science. InfoMat. 2019;1(338):338-358. [10] 孙中体, 李珍珠, 程观剑,等.机器学习在材料设计方面的研究进展[J].科学通报,2019, 64(32):3270-3275. [11] DUAN C, NANDY A, KULIK HJ. Machine learning for the discovery, design, and engineering of materials. Annu Rev Chem Biomol Eng. 2022;13:405-429. [12] SIWAR C, FRANCOIS XC. Machine learning approaches for the prediction of materials properties. APL Mater. 2020;8(8):080701. [13] GRAŽULIS S, MERKYS A, VAITKUS A. Crystallography open database (COD). Mater Model Hand. 2020. [14] CALDERON CE, PLATA JJ, TOHER C, et al. The AFLOW standard for high-throughput materials science calculations. Comput Mater Sci. 2015;108:233-238. [15] KIRKLIN S, SAAL JE, MEREDIG B, et al. The Open Quantum Materials Database (OQMD): assessing the accuracy of DFT formation energies. Npj Comput Mater. 2015;1(1):1-15. [16] RASMUSSEN FA, THYGESEN KS. Computational 2D materials database: electronic structure of transition-metal dichalcogenides and oxides. J Phys Chem C. 2015;119(23):13169-13183. [17] TALIRZ L, KUMBHAR S, PASSARO E, et al. Materials cloud, a platform for open computational science. Sci Data. 2020;7(1):299. [18] KAMAL C, KEVIN FG, ANDREW CE, et al. The joint automated repository for various integrated simulations (JARVIS) for data-driven materials design. Npj Comput Mater. 2020;6(1):173. [19] BORYSOV SS, GEILHUFE RM, BALATSKY AV. Organic materials database: an open-access online database for data mining. PloS one. 2017;12(2):e0171501. [20] ERÉNDIRA R, ROBERTO A, CARLOS C, et al. Data sampling methods to deal with the big data multi-class imbalance problem. Appl. Sci. 2020;10(4):1276. [21] MUHAMEDYEV R. Machine learning methods: an overview. Comput Model New Technol. 2015;19(6):14-29. [22] SIQI W, QIANG L, XIFENG G, et al. Fast and unsupervised outlier removal by recurrent adaptive reconstruction extreme learning machine. Int J Mach Learn Cyb. 2019;10(12):3539-3556. [23] LUAI AS, ZYAD S, BASEL K, et al. Data mining: a preprocessing engine. Comput Sci. 2006;2(9): 735-739. [24] ALQURAISHI M. ProteinNet: a standardized data set for machine learning of protein structure. BMC Bioinform. 2019;20(1):1-10. [25] NG A. Machine learning and ai via brain simulations. Accessed. 2013;3(2):2018. [26] BRYKOV MN, PETRYSHYNETS I, PRUNCU CI, et al. Machine learning modelling and feature engineering in seismology experiment. Sensors. 2020;20(15):4228. [27] COX T, MOTEVALLI B, OPLETAL G, et al. Feature engineering of solid‐state crystalline lattices for machine learning. Adv Theor Simul. 2020;3(2):1900190. [28] GARG M, ANITA G. Preserving integrity in online assessment using feature engineering and machine learning. Expert Syst Appl. 2023;225:120111. [29] HIRA ZM, GILLIES DF. A review of feature selection and feature extraction methods applied on microarray data. Adv Bioinformatics. 2015;2015(13):198363. [30] DAI DB, XU T, WEI X, et al. Using machine learning and feature engineering to characterize limited material datasets of high-entropy alloys. Comput Mater Sci. 2020;175:109618. [31] VERDONCK T, BAESENS B, ÓSKARSDÓTTIR M, et al. Special issue on feature engineering editorial. Mach Learn. 2021. doi: 10.1007/s10994-021-06042-2. [32] GHIRINGHELLI LM, VYBIRAL J, LEVCHENKO SV, et al. Big data of materials science: critical role of the descriptor. Phys Rev Lett. 2015;114(1):105503. [33] METZGER A, TOSCANI M. Unsupervised learning of haptic material properties. Elife. 2022;11:e64876. [34] COURT CJ, COLE JM. Auto-generated materials database of Curie and Néel temperatures via semi-supervised relationship extraction. Sci Data. 2018;5(5):180111. [35] FRANK ES, DEHMER M. Evaluation of regression models: model assessment, model selection and generalization error. Mach Learn Knowl Extr. 2019;1(1):521-551. [36] NOVAKOVIĆ, JASMINA DJ. Evaluation of classification models in machine learning. Theory Appl Math Comput Sci. 2017;7(1):39-46. [37] SAXENA A, PRASAD M, GUPTA A, et al. A review of clustering techniques and developments. Neucomputing. 2017;267(12):664-681. [38] LI M, YIN T, WANG Y, et al. Study of biocompatibility of medical grade high nitrogen nickel-free austenitic stainless steel in vitro. Mater Sci Eng C Bio S. 2014;43:641-648. [39] FINŠGAR M, UZUNALIĆ AP, STERGAR J, et al. Novel chitosan/diclofenac coatings on medical grade stainless steel for hip replacement applications. Sci Rep. 2016;6(1):26653. [40] MAVROGENIS AF, PAPAGELOPOULOS PJ, BABIS GC. Osseointegration of cobalt-chrome alloy implants. J Long Term Eff Med Impl. 2011;21(4):349-358. [41] WANG H, WANG X, QIAN H, et al. The optimal structural analysis of cobalt-chromium alloy (L-605) coronary stents. Comput Meth Biome B. 2021;24(14):1566-1577. [42] 崔振铎, 朱家民,姜辉,等.Ti及钛合金表面改性在生物医用领域的研究进展[J].金属学报, 2022,58(7):837-856. [43] NASR AM, ZAHEDI A, BOWOTO OK, et al. A review of current challenges and prospects of magnesium and its alloy for bone implant applications. Prog Biomater. 2022;11(1):1-26. [44] WENYE YE, ZHANG X, JAKE H, et al. Life prediction for directed energy deposition-manufactured 316L stainless steel using a coupled crystal plasticity-machine learning framework. Adv Eng Mater. 2023;25(10):1527-2648. [45] DUAN H, CAO M, LIU L, et al. Prediction of 316 stainless steel low-cycle fatigue life based on machine learning. Sci Rep. 2015;13(1):6753. [46] SHEN CG, WANG CC, WEI XL, et al. Physical metallurgy-guided machine learning and artificial intelligent design of ultrahigh-strength stainless steel. Acta Mater. 2019;179:201-214. [47] ZHAO DQ, PAN SP, ZHANG Y, et al. Structure prediction in high-entropy alloys with machine learning. Appl Phys Lett. 2021;118(23):231904. [48] CHANG YJ, JUI CY, LEE WJ, et al. Prediction of the composition and hardness of high-entropy alloys by machine learning. JOM. 2019;71:3433-3442. [49] WEN C, ZHANG Y, WANG CX, et al. Machine learning assisted design of high entropy alloys with desired property. Acta Mater. 2019;170(3):109-117. [50] CHEN L, JARLÖV A, SEET HL, et al. Exploration of V-Cr-Fe-Co-Ni high-entropy alloys with high yield strength: a combination of machine learning and molecular dynamics simulation. Comput Mater Sci. 2022;217:111888. [51] MILONE D, RISITANO G, PISTONE A, et al. A new approach for the tribological and mechanical characterization of a hip prosthesis trough a numerical model based on artificial intelligence algorithms and humanoid multibody model. Lubricants. 2022;10(7):160. [52] ZOU C, LI J, WANG WY, et al. Integrating data mining and machine learning to discover high-strength ductile titanium alloys. Acta Mater. 2021;202(11):211-221. [53] IZONIN R, TKACHENKO M, GREGUS M, et al, Pnn-svm approach of ti-based powder’s properties evaluation for biomedical implants production. Comput Mater Cont. 2022;71(3):5933-5947. [54] WU CT, CHANG HT, CHEN SW, et al. Machine learning recommends affordable new Ti alloy with bone-like modulus. Mater Today, 2020;34(1):41. [55] RAJ AC, SHUBHABRATA D. Designing Ti alloy for hard tissue implants: a machine learning approach. J of Materi Eng and Perform. 2023;7(23):07912-11665. [56] LIU X, PENG Q. Machine learning assisted prediction of microstructures and young’s modulus of biomedical multi-component β-Ti alloys. Metals. 2022;12(5):796. [57] ZHENG K, LIU HJ. Investigation on wear prediction model of dental restoration material based on ensemble learning. Mater Res Innov. 2014;18(2):S2-987-S2-991. [58] BHANDARI U, RAFI MR, ZHANG C, et al. Yield strength prediction of high-entropy alloys using machine learning. Mater Today Comm. 2020;26:101871. [59] SUN Y, LU Z, LIU X, et al. Prediction of Ti-Zr-Nb-Ta high-entropy alloys with desirable hardness by combining machine learning and experimental data. Appl Phys Lett. 2021;119(20):14-23. [60] ZHOU C, ZHANG Y, STASIC J, et al. Hardness predicting of additively manufactured high‐entropy alloys based on fabrication parameter‐dependent machine learning. Adv Eng Mater. 2022;25(8):2201369. [61] JAAFREH R, KANG YS, HAMAD K, et al. Brittle and ductile characteristics of intermetallic compounds in magnesium alloys: a large-scale screening guided by machine learning. J Magnes Alloy. 2022;11(1):392-404. [62] CURTAROLO S, SETYAWAN W, HART GLW. AFLOW: an automatic framework for high-throughput materials discovery. J Comput Mater Sci. 2012;58:218-226. [63] WANG YW, XIE T. High-throughput calculations combining machine learning to investigate the corrosion properties of binary Mg alloys. J Magnes Alloy. 2022;12(2):2213-9567. [64] SUH JS, SUH B. Machine learning-based design of biodegradable Mg alloys for load-bearing implants. Mater Design. 2022;225(12):111442. [65] LU ZX, SHU JS, KEYING H, et al. Prediction of Mg alloy corrosion based on machine learning models. Adv Mater Sci Eng. 2022;9597155. [66] LI MH, MESBAH M. Mechanical strength estimation of ultrafine-grained magnesium implant by neural-based predictive machine learning. Mater Lett. 2021;305(10):130627. [67] MI XX, TIAN LJ. A reverse design model for high-performance and low-cost magnesium alloys by machine learning. J. Comput Mater Sci. 2021;201:110881. [68] XU X, WANG L, ZHU G, et al. Predicting tensile properties of AZ31 magnesium alloys by machine learning. JOM. 2020;72(11):3935-3942. [69] MI XX, JING XR. A machine learning enabled ultra-fine grain design strategy of Mg-Mn-based alloys. J Mater Res Technol. 2023;23:4576-4590. [70] LIU Y, WANG L, ZHANG H, et al. Accelerated development of high-strength magnesium alloys by machine learning. Metall Mater Trans A. 2021;52(3):943-954. |
| [1] | 余伟杰, 刘爱峰, 陈继鑫, 郭天赐, 贾易臻, 冯汇川, 杨家麟. 机器学习在腰椎间盘突出症诊治中的优势和应用策略[J]. 中国组织工程研究, 2024, 28(9): 1426-1435. |
| [2] | 程进荟, 伍 权, 彭 敏, 黄昌丽, 田会敏, 李 洋. 低能量密度下多孔钛的选区激光熔化制备及性能评价[J]. 中国组织工程研究, 2024, 28(5): 664-668. |
| [3] | 王建春, 杨树青, 苏 欣, 王宏远. 不同含量B2O3对生物活性玻璃支架力学性能与生物活性的影响[J]. 中国组织工程研究, 2024, 28(5): 712-716. |
| [4] | 兰伟伟, 于耀东, 黄 棣, 陈维毅. Mg-Zn-Ca合金的体外降解行为[J]. 中国组织工程研究, 2024, 28(5): 717-723. |
| [5] | 张艺海, 商 鹏, 马奔原, 侯光辉, 崔伦旭, 宋万振, 齐德瑄, 刘艳成. 径向梯度三周期极小曲面骨小梁支架结构设计与力学性能分析[J]. 中国组织工程研究, 2024, 28(5): 741-746. |
| [6] | 刘安宏, 蔡萌萌, 韩 笑, 王战会. 医用镁合金元素选择的研究现状[J]. 中国组织工程研究, 2024, 28(5): 777-782. |
| [7] | 徐文飞, 明春玉, 梅其杰, 袁长深, 郭锦荣, 曾 超, 段 戡. 机器学习鉴定KDELR3作为骨关节炎缺氧特征基因的实验验证[J]. 中国组织工程研究, 2024, 28(21): 3431-3437. |
| [8] | 袁长深, 廖书宁, 李 哲, 吴思萍, 陈乐伟, 刘晋邑, 李彦宏, 段 戡. 机器学习联合生物信息学鉴定骨关节炎细胞衰老关键基因及验证[J]. 中国组织工程研究, 2024, 28(20): 3196-3202. |
| [9] | 范以东, 秦 刚, 苏国威, 肖世富, 刘俊良, 李威材, 吴广涛. 基于人工神经网络骨关节炎诊断模型的建立与分析[J]. 中国组织工程研究, 2024, 28(16): 2550-2554. |
| [10] | 夏 天, 李炳霖, 肖发源, 郑恩泽, 陈跃平. 类风湿关节炎铁死亡特征基因CeRNA网络构建及免疫表现[J]. 中国组织工程研究, 2024, 28(16): 2561-2567. |
| [11] | 袁长深, 廖书宁, 李 哲, 官岩兵, 吴思萍, 胡 琪, 梅其杰, 段 戡. N6-甲基腺苷相关调节因子与骨关节炎:生物信息学和实验验证分析[J]. 中国组织工程研究, 2024, 28(11): 1724-1729. |
| [12] | 王彦金, 周英杰, 柴旭斌, 禚汉杰. 3D打印多孔钛合金椎间融合器在颈椎前路椎间盘切除植骨融合中应用效果与安全性的Meta分析[J]. 中国组织工程研究, 2023, 27(9): 1434-1440. |
| [13] | 贺垠皓, 李晓声, 陈宏文, 陈铁柱. 3D打印多孔钽金属治疗发育性髋关节发育不良:现状及应用前景[J]. 中国组织工程研究, 2023, 27(9): 1455-1461. |
| [14] | 于文强, 任富超, 石国宏, 许苑晶, 刘同有, 谢幼专, 王金武. 脑卒中后下肢步态分析的方法与应用[J]. 中国组织工程研究, 2023, 27(8): 1257-1263. |
| [15] | 刘佳辛, 贾 鹏, 门玉涛, 刘 璐, 王烨明, 叶金铎. 基于三周期极小曲面骨小梁结构的设计及优化[J]. 中国组织工程研究, 2023, 27(7): 992-997. |
随着大数据和计算模拟的广泛应用,医用金属材料研究积累了大量数据,推动了对计算科学第4范式的需求[7]。机器学习方法位于计算机科学和统计学的交叉点,是人工智能和数据科学的核心[8],它利用大规模数据进行模型训练,成为解决实际问题的核心方法。可以显著降低计算资源消耗,缩短材料研发周期,并且通过利用大数据训练模型以解决实际问题,成为替代计算模拟甚至重复实验测试的最经济高效的方法之一[9],因此,其在材料领域得到了广泛的应用,例如孙中体等[10]和DUAN等[11]都针对机器学习在材料领域的应用做了系统的阐述和总结。
在医用金属材料领域,机器学习的应用也取得显著成果。机器学习在医用金属材料方面的研究包含2个方面:特性基础研究和临床应用。在特性基础研究方面,机器学习具有处理大规模实验数据、挖掘隐藏特性关联、快速预测特性等优点,有助于优化合金组分和工艺参数,缩短研发周期,降低实验成本。然而,模型的准确性受数据质量限制,遇到复杂模型会导致难以解释和理解等缺点。在临床应用方面,机器学习可以根据患者生理数据个性化定制植入物、预测植入物寿命和辅助手术规划。但进行临床验证需要的时间和成本较高,并且有限的临床数据,无法考虑个体差异,缺少泛化性。由此可见,机器学习在医用金属材料特性研究的基础阶段,尤其是材料设计和性能预测方面应用最好。因为在此阶段,可以充分利用大规模的实验数据,快速挖掘材料特性之间的关联,帮助优化材料设计,缩短研发周期。而在临床应用方面,虽然机器学习有着潜力,但目前还面临一些挑战,需要进一步的临床验证和数据隐私保护措施。因此,在临床应用中的推广可能相对较慢,需要更多的研究和实践。
因此,该综述将重点聚焦于机器学习在医用金属材料特性基础研究方面的应用。通过结合机器学习算法和高通量计算,建立机器学习模型并挖掘大规模实验数据,实现高效分析,旨在揭示材料本征属性与材料工艺之间的关联,为医用金属材料的设计提供指导和决策支持,从而高效地开发具备优异医用适用性的金属材料。此外,机器学习在医用金属材料性能研究中还能为组织工程领域提供有力支持。通过分析实验数据和材料特性,机器学习能够挖掘不同金属材料与人体组织之间的关联,辅助优化植入物或假体的设计,预测材料的耐腐蚀性、力学性能等特性,为组织工程的材料选择和设计提供重要指导。此外,机器学习还可基于患者生理数据和材料特性,实现个性化植入物的设计,进一步提高治疗效果。 中国组织工程研究杂志出版内容重点:生物材料;骨生物材料;口腔生物材料;纳米材料;缓释材料;材料相容性;组织工程
1.1.1 检索人及检索时间 第一作者在2023年3-4月进行检索。
1.1.2 检索文献时限 检索时间范围重点在2013年1月至2023年4月,同时纳入少量远期经典相关文献。
1.1.3 检索数据库 中国知网数据库、PubMed数据库、X-MOL数据库和Web of Science数据库。
1.1.4 检索词 中文检索词为“医用金属材料机器学习,医用钛合金,医用镁合金,医用金属材料性能”,英文检索词为“machine learning medical metal materials,medical stainless steel alloy,medical cobalt-chromium alloy,medical titanium alloy,medical magnesium alloy”。
1.1.5 检索文献类型 研究原著和综述。
1.1.6 手工检索情况 对文献中高价值的参考文献,先阅读文题,再以标题进行检索,阅读全文。
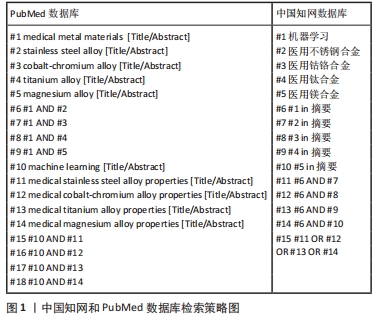
1.1.7 检索策略 以PubMed和中国知网数据库为例,检索策略见图1。
1.2 入组标准
1.2.1 纳入标准 ①介绍医用金属材料的应用和研究进展;②医用金属材料特性的研究;③机器学习在各类医用金属材料应用现状的研究。
1.2.2 排除标准 ①研究老旧并且数据库中重复的文献;②与文章主题关联性较差的文献。
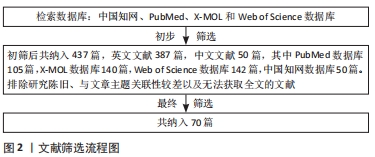
1.3 文献质量评估及数据提取 在437篇文章中,英文387篇,中文文献50篇,通过阅读文献的题目和摘要进行初步筛选,继而仔细阅读全文排除研究陈旧、与文章主题关联性较差以及无法获取全文的文献,最后筛选出70篇文献进行综述撰写[1-70],包括英文69篇,中文1篇,其中PubMed数据库5篇,X-MOL数据库44篇,Web of Science数据库20篇,中国知网数据库1篇,见图2。
3.1 既往他人在该领域研究的贡献和存在的问题 近年来,机器学习在医用材料中的使用逐渐广泛,研究人员使用机器学习算法对大规模材料数据库进行高通量筛选,预测不同医用合金材料的性能,如硬度、屈服强度及腐蚀性能等,从而加速医用材料设计和优化过程,并且通过机器学习算法预测材料的晶体结构和微观组织,发现新型材料的相组成、相稳定性等,有助于提高医用金属材料的性能和可靠性。同时研究人员应用机器学习算法辅助合金设计,选择最优合金组分,提高材料的特定性能,例如耐腐蚀性、力学性能等,有助于研制更适用于医疗领域的金属材料。人们还通过机器学习模型,预测医用金属材料的力学性能、腐蚀性能等物理性质,为材料应用提供重要参考。由于复杂系统计算量庞大且成本高,针对不同金属材料系统,需要重新参数化和建模,导致耗时繁琐,而金属材料的计算模拟涉及大量原子和复杂相互作用,需要大量计算资源和时间。另外,现有理论不能满足需求,因为金属材料的性能和结构涉及多个尺度,目前的计算模拟工具难以覆盖所有尺度,并且在多尺度和跨尺度设计中仍存在挑战,需要有效集成不同方法并解决尺度之间的信息传递和耦合问题。因此使用机器学习模型弥补了这些缺点,同时可高效的进行计算。然而,目前在机器学习研究医用金属材料领域仍存在一些问题。首先,当前使用的机器学习算法相对滞后,无法满足医用金属材料设计和开发的精准控制和全面需求,难以对材料的特性之间的联系进行建模和预测,由于机器学习是“黑匣子”工程,研究者们可以通过输入数据产生预测结果,但其内部结构和参数是不知道的,即模型的输出是基于哪些输入特征和规律进行的,因此模型的解释性非常重要。
金属材料领域的实验和数据收集缺乏标准化,形成标准化的数据量相对较少以及临床验证消耗时间较长。缺乏标准化是在进行实验研究时,不同的研究团队可能采用不同的实验方法、测试条件、数据处理等,导致得到的数据存在差异,不一致性,会导致研究人员在进行文献调研或数据对比时可能会遇到困难,这也限制了对材料性能和行为的全面理解和准确评估。除了数据量少之外,机器学习模型的泛化性能在面对未知条件或新材料时可能会受到限制,正因为模型的泛化能力较低,导致机器学习模型在中低至中高周期疲劳过程中的测试误差会相应增大,这是因为模型未能识别晶体的其他疲劳过程及晶体数据的复杂性,因此误差会增大。最后,机器学习在图像处理任务中的高维数据集处理和降维算法仍面临挑战,由于高维数据有数千或数百万个特征的特征,这导致计算耗时耗力,同时对于高维图像数据,如何选择和提取最具有代表性的特征是一个关键问题。有效的特征选择和提取方法能够帮助减少维度并保留最重要的信息,但找到最佳的特征集仍然具有挑战性。
3.2 作者综述区别于他人他篇的特点 由于机器学习在医用金属材料领域的研究属于医工交叉的领域,在最近几年该研究越来越广泛,但目前对于机器学习在医用材料领域的应用系统整理的较少,因此该综述与其他机器学习在材料中的应用不同的是文章专注于医用金属材料,并重点探讨与医学适用性相关的特性,如耐腐蚀性和力学性能。通过专注于这些关键特性,文章为开发新型医用金属材料提供了有针对性的指导,并从专业的角度探讨了医用金属材料在医学领域的应用和挑战。同时,文章强调了耐腐蚀性和力学性能等医用适用性特性的重要性,以帮助发现更优异的金属材料,为医用材料的设计和开发提供了有价值的参考。
3.3 综述的局限性 针对医用金属材料在临床上的应用较少,这是由于临床验证的过程时间较长,因此针对该内容的介绍较少,并且该综述只涵盖了医用金属材料的力学性能以及腐蚀性能,而对医用金属材料的生物相容性没有涵盖,这是因为生物相容性涉及动物实验等一些临床试验,试验周期长,所以该内容的文章较少,无法形成系统的综述论点。
3.4 综述的重要意义 该综述对机器学习在医用金属材料领域的应用进行全面综合,涵盖了不同机器学习算法在材料设计、性能预测、合金优化等方面的应用,旨在提供一个全景式的视角,使读者能够全面了解机器学习在医用金属材料中的研究现状并进一步促进医用金属材料的设计与开发。
3.5 课题专家组对未来的建议 未来如何解决存在问题,建议按照以下方法来进一步改良。首先,针对机器学习模型滞后的问题,可采用更先进的方法以提高模型性能,例如:深度学习、特性之间的联系和可解释性问题可采用机器学习与知识谱图相结合,知识谱图可揭示特性之间的联系,使机器学习可解释。其次,数据标准化问题,开发和建立输入表征数据和输出测试测定的通用标准,以确保收集的数据具有可比性。再次,提高模型的泛化能力,可以添加正则化项到损失函数中,防止模型过拟合训练数据,使其更关注重要的特征,避免学习到噪声,还可以使用交叉验证技术评估模型性能,选择最优的超参数配置,从而提供更好的泛化性能。同时可以将多个模型集成,如Bagging和Boosting等方法,可以降低模型的方差,提高泛化能力。最后,图像处理任务中可使用有效的特征选择方法,选择那些对于图像分类或回归任务最有意义的特征,还可以使用特征提取技术将高维图像数据转换为更具有代表性的低维特征空间。例如,可以使用卷积神经网络(CNN)的中间层输出作为图像特征,或者采用基于哈尔小波、局部二值模式(LBP)等的传统图像特征提取方法降低高维数据集处理和降维算法的复杂度。最后,积极推进不同学科研究人员之间密切合作,跨学科、跨领域交流,实现构建数据量完整且标准的数据集,进一步促进机器学习在各个学科领域中应用发展。 中国组织工程研究杂志出版内容重点:生物材料;骨生物材料;口腔生物材料;纳米材料;缓释材料;材料相容性;组织工程
#br#
文题释义:
医用金属材料:是在医学领域中广泛应用的特殊金属材料。这些金属材料通常具有优异的生物相容性、耐腐蚀性和力学性能。常见的医用金属包括不锈钢、钛合金和钴铬合金等,由于其良好的特性,医用金属材料在植入物制造、手术器械、牙科修复和骨科手术等领域得到广泛应用。机器学习:是人工智能领域的一个分支,它是通过构建和训练算法来使计算机系统从数据中学习,并根据学习的知识做出决策或预测。机器学习的核心思想是通过分析大量数据,找出其中的模式和规律,并用这些规律来做出预测或分类。
综上所述,该综述的创新点在于专注于研究医用金属材料,并着眼于医用适用性的相关特性(耐腐蚀性和力学性能)。相较于以往的机器学习在材料领域的综述,文章将重点放在医用金属材料的具体应用和挑战上,对新型医用材料的开发提供了指导作用,也为医学领域的金属材料研究提供了新颖且专业的视角。同时,文章目的是通过强调耐腐蚀性和力学性能等医用适用性特性的重要性,有助于发现更优异的金属材料,为医用领域的材料设计和开发提供有价值的参考。此外,机器学习与医用金属材料的特性研究紧密结合,突出其在组织工程中的关键作用,为医学领域的金属材料研究提供全面而深入的探讨。该综述从机器学习的基本工作流程出发,详细介绍了机器学习在不锈钢共基合金、钴铬合金、钛合金和镁合金特性研究上的应用,展示了其在医用金属材料研究中的重要潜力。最后,文章通过对机器学习在医用金属材料领域的应用进行总结和分析其不足,为未来研究提供了新的思路和方向。
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||