2 分析步骤 Analysis steps
安装Bilog-MG软件后,点击“file-new”,新建“bilog”的文件,见图2。Bilog-MG软件的菜单栏包括file、Edit、Setup、Data、Techincal、Save、Run、Output、View、Options、Workspace、Window和Help。
2.1 定义基本情况和分析模型
2.1.1 定义基本情况 点击“Setup-General”,“Job description”用于定义基本情况。“Title”和“Commend”选项框可以空缺,也可以输入内容;本例在“Title”输入“bilog”。在“Total number of items”输入“4”,表示一共纳入4个条目,对应的语法是“> INPUT NTOTAL=4”;其他选项均使用默认的“1”。“Number of subtests”表示亚测试的数量;“Number of test form”表示测试形式的数量;“Number of examinee group”表示测试的组别,如果选定,则可以编辑“Reference group”;见图3。
2.1.2 定义分析模型 点击“Model”,“Response model”包括单参数模型(1-Parameter Logistic),双参数模型(2-Parameter Logistic)和三参数模型(3-Parameter Logistic)。本例选择单参数模型,对应的语法是“> Global NPARM=1”。“Response function metric”选择“Logistic”,表示使用Logistic公式,对应的语法是“> Global LOGISTIC”,“Special models”中选择默认的“Standard”;如果开展条目功能差异,则需要选择“Differential item functioning”,见图4。“Response”窗口用于定义条目的选项,本例的条目都是二分类(0和1),因此在“Number of response alternative”中输入“2”,“Response codes”中输入“01”,见图5。“Label”窗口用于修改测试和条目的名字,本例采用默认的名字(TEST0001、ITEM0001等)。
2.2 定义分析条目和估计方法 点击“Setup-Item analysis”,“Subtest”用于定义每个测试分析的条目,本例4个条目都在一个测试,因此在“Subtest length”中输入“4”,见图6。“Advanced”用于定义估计方法,包括收敛标准(Convergence criterion)、EM周期的最大值(Maximum number of EM cycle)、牛顿周期的最大值(Maximum number of Newton cycle)、卡方拟合统计量(Chi-square item fit statistics)、正交点的数量(Number of quadrature points)和条目限制(Prior item constraints),本例都用默认值,见图7。
2.3 定义测试评分 点击“Setup-Test scoring”,“General”用于定义测试评分的基本情况,可以定义估计方法(Method)、潜在变量的分布(Latent distributions)、导入条目参数(Import item parameter for S)、Biweight条目(Biweight items)、组别拟合统计量(Group level fit statistics)和列表评分(List scores)。本例都采用默认值。“Rescaling”用于定义重新估计得分的方法,本例不需要重新估计得分,见图8。
2.4 定义数据基本情况 点击“Data-Examinee data”,“General”窗口用于定义数据的基本情况。ID号的数量(Number of case ID characters)输入“3”,对应的语法是“Input NIDCH=3”。分析样本量(Case samples)、加权(Case weights)、特定的分组(Group specific subtests)、外部能力准则和标准误(External ability criterion and standard error)都采用默认的选项,见图9。
定义数据格式,点击“Data file”。点击“Data file name”中的“Browse”,选择“F:\Example”中的“Bilog.dat”文件(图1)。“Read as fixed-column record”中的“Case ID”中分别录入“1”和“3”,表示第1-3列是ID。“Response string”中分别录入“5”和“8”,表示第5-8列是条目;点击右下角的“Set format”,“Format string”选项框会出现“3A1,1X,4A1”,见图10。“Enter Data”窗口可以查看具体的数据。点击右上角的“Open”,系统会导入“F:\Example\ Bilog.dat”的数据,见图11。
2.5 定义条目的正确答案 点击“Data-Item keys”,“Answer key”用于定义条目的正确答案。如果是二分类条目,“1”是默认的正确答案,这时不用定义正确答案。如果是多分类资料,只有一个正确答案,需要对答案进行定义,在“Answer key”中依次录入4个选项的答案,见图12。“Data-Group-level data”主要用于定义组别水平的数据。
2.6 保存数据 保存对应的资料,点击菜单栏的“Save”,出现图13,可用于保存Bilog分析中的所有数据,默认的保存路径跟语法的路径一致。
2.7 生成语法 执行程序,建立语法,点击“Run-Build syntax”,见图14。语法为:
> GLOBAL DFName=’F:\Example\Bilog.dat’, NPArm=1;
> LENGTH NITems=(4);



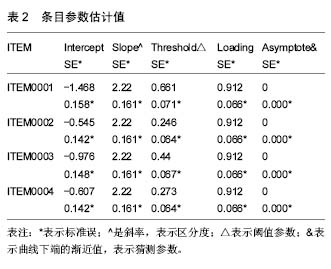
运行程序分为3个步骤:①“Run-Classical statistics only”,进行经典统计分析。如果运行不成功,跳出“Run incomplete”的对话框;运行成功,跳出“Run successful”的对话框,可以在菜单栏“Output-Bilog PH1”查看相应的结果,经典统计分析给出了每个条目答对的人数,百分比等信息,主要结果见表1。其中“TRIED”表示总例数,“RIGHT”表示答对的例数,“PCT”表示答对的百分比(%);②“Run-Calibration only”,进行校准分析,运行成功后可以开展第3步。可以在菜单栏“Output-Bilog PH2”查看相应的结果,校准分析给出了每个条目的参数结果,本例选用单参数模型,因此这里只给出了阈值参数,结果见表2。所有条目的区分度参数(Slope)均为2.22,猜测参数(Asymptote)均为0。阈值参数(Threshold)显示ITEM0001的难度最大,说明该条目最难得高分;ITEM0002的难度最小,说明该条目最容易得高分;③“Run-Scoring only”,进行评分分析。这里给出了每个对象的能力参数估计值,并给出了整个分析的信度系数:“RELIABILITY: 0.7395”。可以
在菜单栏“Output-Bilog PH3”查看相应的结果。结果给出了每个测试者的能力参数。
3个步骤都运行成功,点击“Run-Plot”可查看各种分析图,包括条目特征曲线(ICC),条目信息曲线(Item information curves),总体信息曲线(Total information curves)等,见图15。
.jpg)
.jpg)