中国组织工程研究 ›› 2026, Vol. 30 ›› Issue (36): 9589-9596.doi: 10.12307/2026.899
• 组织构建临床实践 clinical practice in tissue construction • 上一篇 下一篇
融合遗传因素的糖尿病预测及影响因素分析
刘 怡1,卢加荣2,吴建勇1
- 1新疆特殊环境与健康研究重点实验室,新疆医科大学公共卫生学院,新疆维吾尔自治区乌鲁木齐市 830017;2新疆财经大学统计与数据科学学院,新疆维吾尔自治区乌鲁木齐市 830012
Diabetes prediction and analysis of influencing factors integrating genetic information
Liu Yi1, Lu Jiarong2, Wu Jianyong1
- 1Key Laboratory of Special Environment and Health Research in Xinjiang, School of Public Health, Xinjiang Medical University, Urumqi 830017, Xinjiang Uygur Autonomous Region, China; 2School of Data and Statistical Sciences, Xinjiang University of Finance and Economics, Urumqi 830012, Xinjiang Uygur Autonomous Region, China; 3College of Statistics and Data Science, Xinjiang University of Finance and Economics, Urumqi 830012, Xinjiang Uygur Autonomous Region, China
摘要:

文题释义:
糖尿病:是一种以慢性高血糖为核心特征的代谢性疾病,发病机制涉及胰岛素分泌缺陷或胰岛素抵抗,导致糖、脂肪、蛋白质代谢紊乱。糖尿病的典型临床表现为多饮、多食、多尿及体质量下降,长期未控制可引发心脑血管疾病、糖尿病肾病、视网膜病变等严重并发症。
机器学习:是人工智能的核心分支,通过算法使计算机从数据中自动学习规律,并用于预测或决策。机器学习的核心任务包括分类、回归、聚类等,常用方法如决策树、支持向量机、神经网络等。在医学领域,机器学习能处理高维、非线性数据(如基因数据、临床指标),挖掘潜在关联,提升疾病预测精度。
背景:早期风险评估与准确诊断对于临床防治糖尿病具有重要意义。遗传因素在糖尿病发病机制中起重要作用,但目前多数研究对遗传因素在风险建模中的融合不足。
目的:构建融合遗传因素、人体测量学指标及胰岛素代谢指标的综合特征数据集,基于该数据集提出一种可解释性糖尿病预测模型,实现糖尿病的早期风险评估和预测。
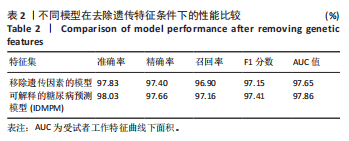
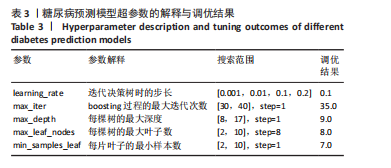
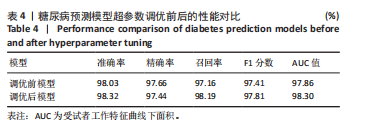
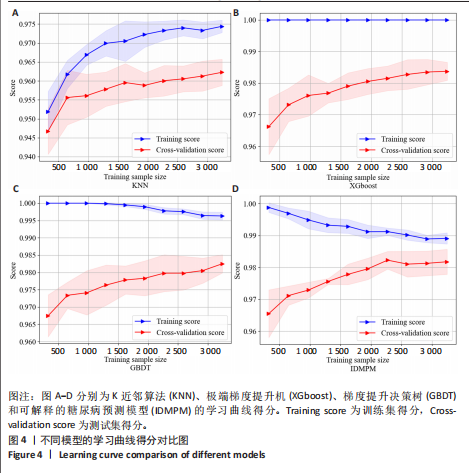
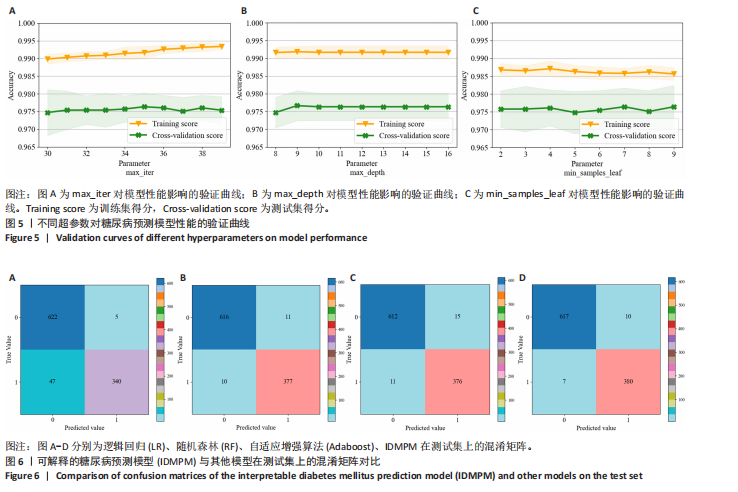
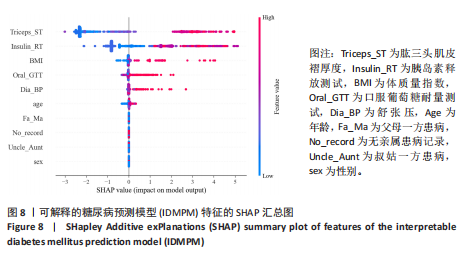
方法:使用公开数据平台Kaggle网站提供的糖尿病预测竞赛数据集,共纳入有效样本5 070 例,其中糖尿病组1 936 例、非糖尿病组3 134例。基于HistGBDT算法对融合特征数据集进行模型训练,通过网格搜索方法优化模型超参数,采用准确率、精确率、召回率、F1分数和受试者工作特征曲线下面积(AUC)等指标评估模型性能;引入SHAP解释框架,识别模型中主要影响糖尿病风险的关键特征,提升模型可解释性。通过消融实验验证融合遗传因素特征的重要性。
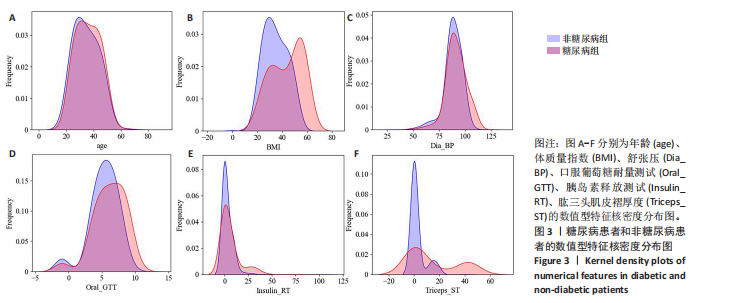
结果与结论:可解释性糖尿病预测模型在准确率(98.03%)、精确率(97.66%)、召回率(97.16%)、F1 分数(97.41%)及 AUC(97.86%)等指标上均优于现有主流模型,性能提升1%-4%。消融实验显示,融合遗传因素的特征集能够更全面有效地捕捉糖尿病风险特征。SHAP分析表明,肱三头肌皮褶厚度、胰岛素释放测试、体质量指数、口服耐糖量测试、舒张压是影响糖尿病发病风险的主要特征,模型的可解释性分析为糖尿病的早期识别和个体化健康管理提供了理论基础和技术支持。
https://orcid.org/0009-0001-9290-2727(刘怡)
中国组织工程研究杂志出版内容重点:干细胞;骨髓干细胞;造血干细胞;脂肪干细胞;肿瘤干细胞;胚胎干细胞;脐带脐血干细胞;干细胞诱导;干细胞分化;组织工程
中图分类号: